数据中心光互连的演进方向,是不断缩短芯片与光器件之间的铜互连走线。越往下一代,铜线用得越少,光通路的占比越来越高。
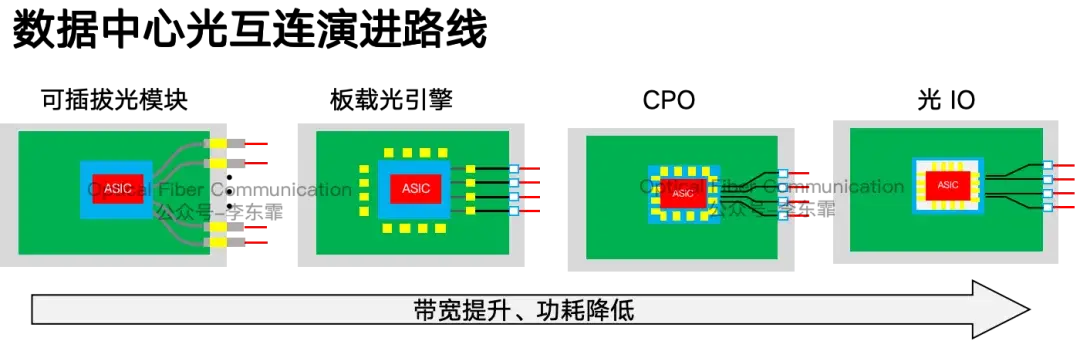
从 QSFP 可插拔模块、BGA/LGA 板载光引擎,到先进封装 CPO 和片上光 IO,封装逐步走向集成化,单光引擎速率也从 100G、400G、800G 一路提升到 12.8T 及以上。
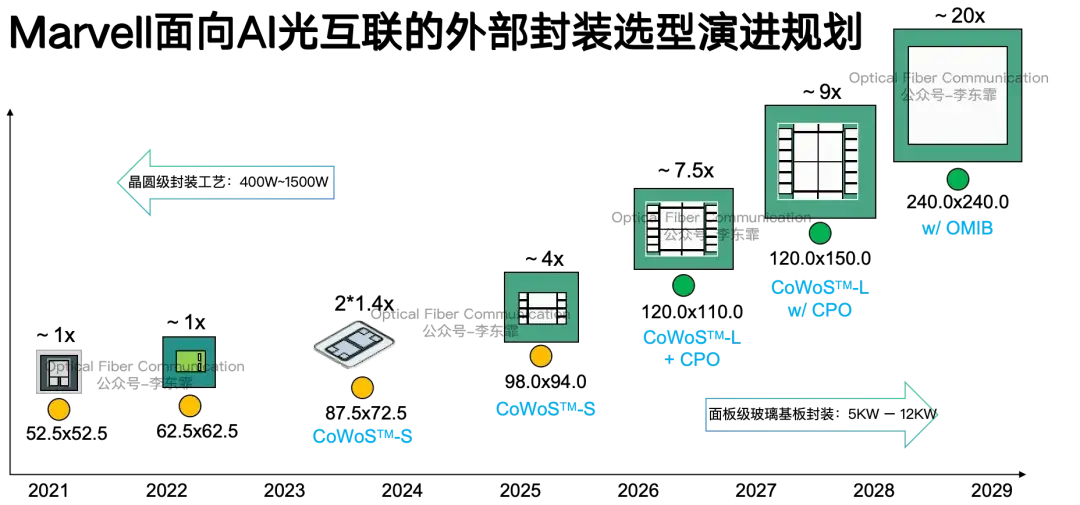
今年 OFC 2026 上,Marvell 介绍了它的外部封装选型的技术路线。
Marvell 的 Scale Up/out 的一些观点+102.4T CPO 交换机
2021 到 2022 年,Marvell 主要采用传统小尺寸封装,面积分别为 52.5×52.5 和 62.5×62.5。这类封装只能适配 QSFP 可插拔光模块,支持 100G、400G、800G 速率。
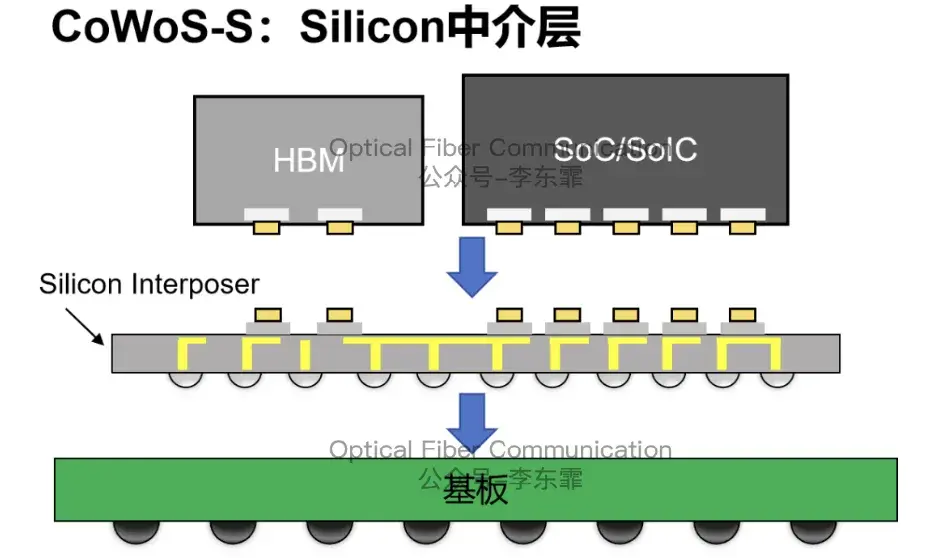
2023 到 2025 年,Marvell 选用台积电 CoWoS-S 硅中介层封装,承载自家的 CPO 光子架构,支持板载 BGA/LGA 光引擎,速率达到 800G 到 1.6T。
2025 到 2028 年,Marvell 将采用 CoWoS-L 实现 CPO,光引擎直接贴装在封装中介层或基板表面。
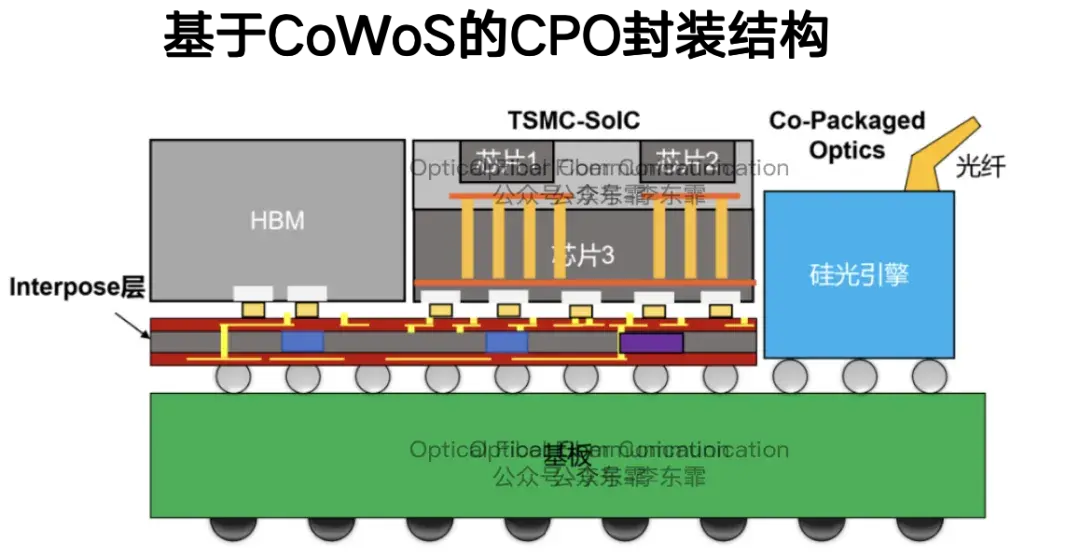
台积电:基于 COUPE 与 CoWoS 封装的 CPO 演进路线
CoWoS-L 的中介层同时包含 LSI(局部硅互连)和 RDL。需要高密度互联的位置用硅桥连接,其他地方用 RDL 或基板走线。
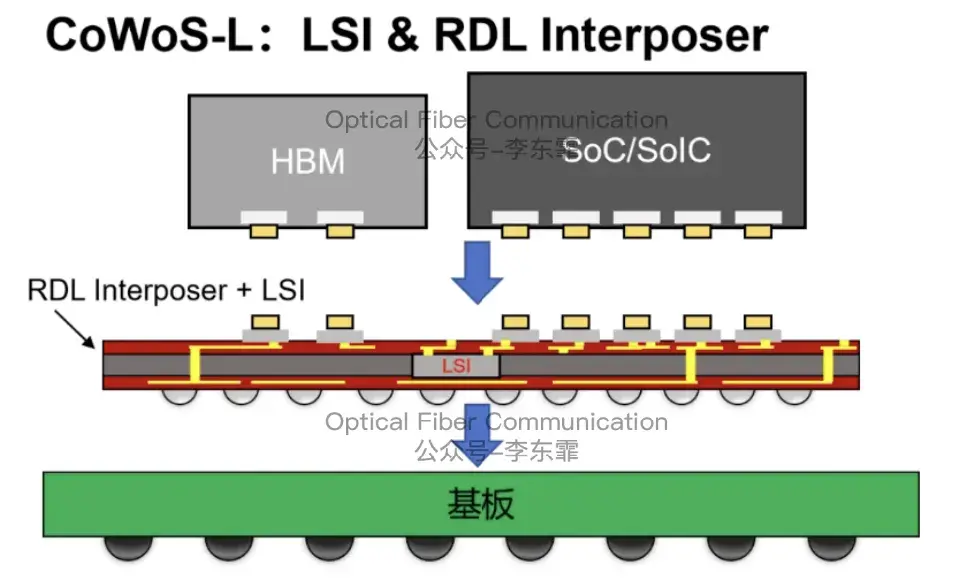
台积电:基于 COUPE 与 CoWoS 封装的 CPO 演进路线
其中,XPU、IO die 和 CPO 三颗裸片并排平铺在硅中介层上,通过 D2D 横向铜线互连完成光电互通。
但随着封装尺寸不断增大,引脚间距持续缩小,大量铜线 D2D 互连、多层 SerDes 和电光转换带来额外的功耗。
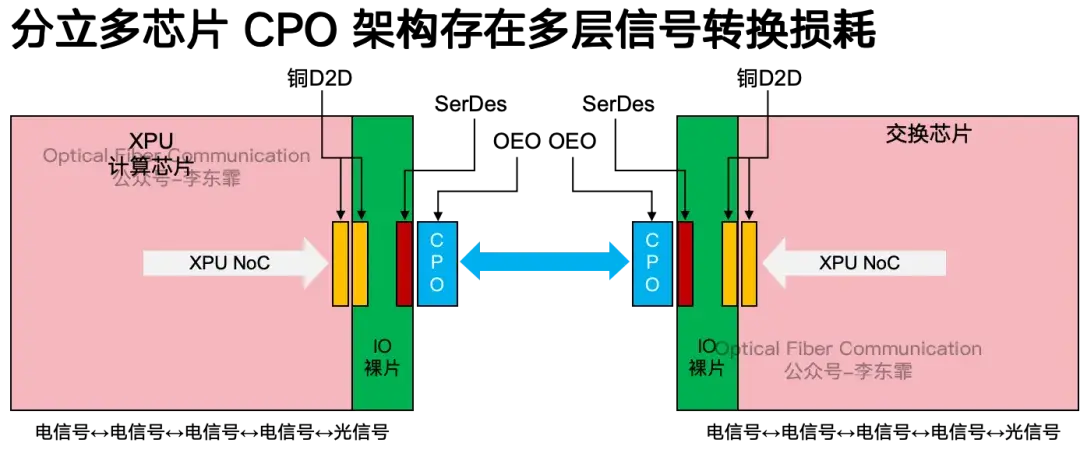
带宽也受限于走线长度和趋肤效应。高频下趋肤效应带来明显的射频损耗,想要提升带宽只能增加通道数或加长铜线,但这又会进一步推高功耗和时延。
同时,算力和存储裸片的面积持续扩大,外围 I/O 铜线互连的距离同步拉长。铜线电信号的传输时延随走线长度线性增加,走线越长,时延越高。
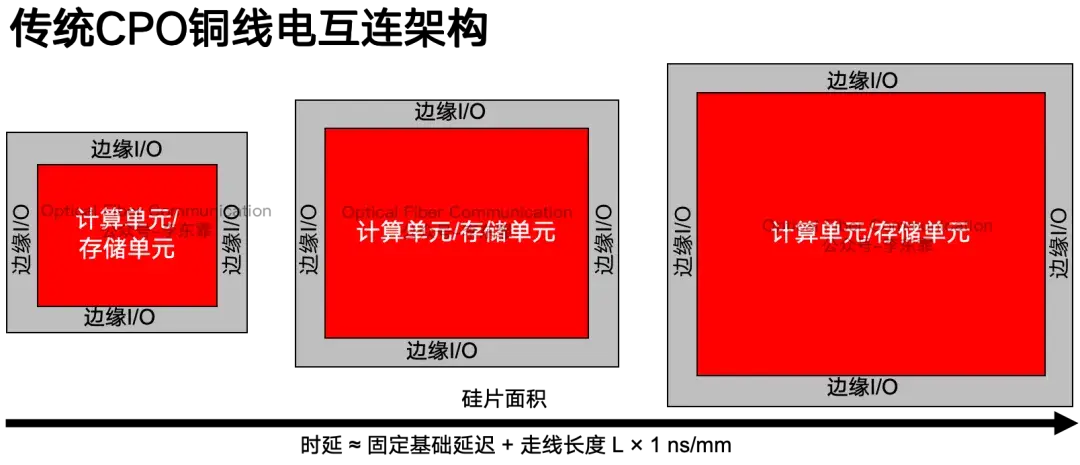
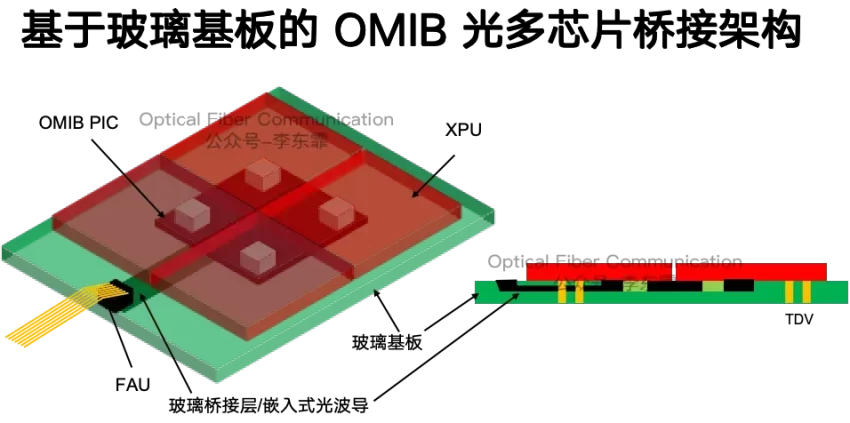
因此到了远期 2029 年,Marvell 计划采用收购 Celestial AI 后获得的 OMIB 玻璃基板封装,玻璃基板内嵌光波导,落地下一代 Optical I/O 全光互联,整体封装规模预计达到初代方案的 20 倍。我们在上一篇文章中提到过 Intel 的电硅桥 EMIB 方案。
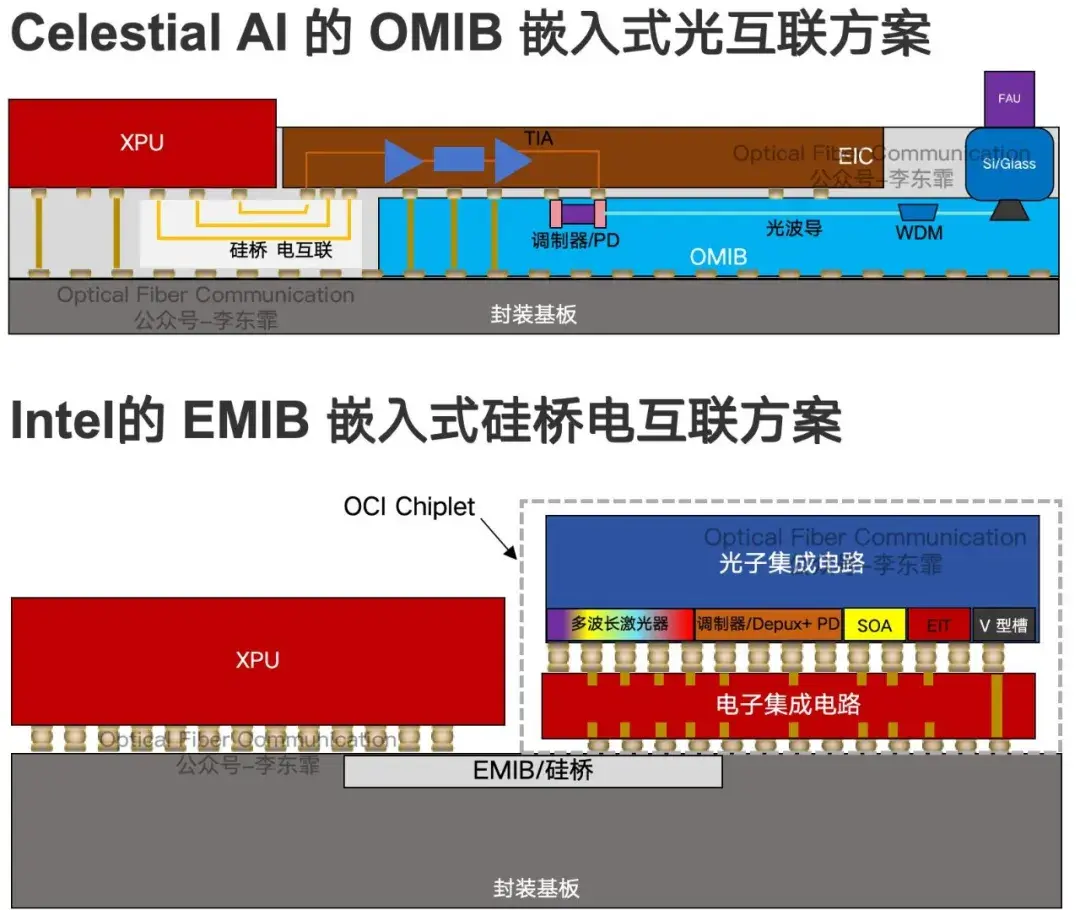
海思 / Intel:用于 CPO 的 SiN-SOI 微环调制器
玻璃基板热膨胀系数低、耐高温,支持 240mm 超大面板级封装。封装规模达到初代的 20 倍,整机可承载 5kW 到 12kW 的超高算力。
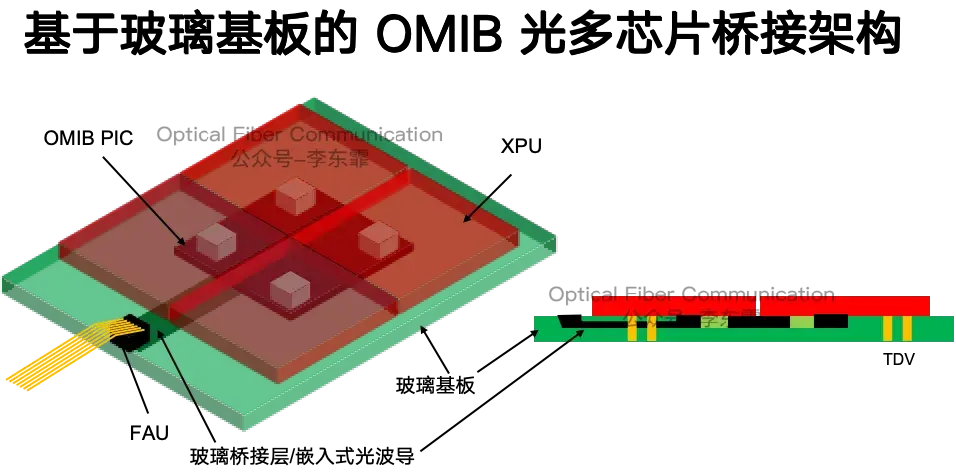
上下裸片贴装在玻璃芯基板上,基板内部同时排布金属电走线和嵌入式光波导,通过 TDV 垂直通孔实现层间高密度互联。
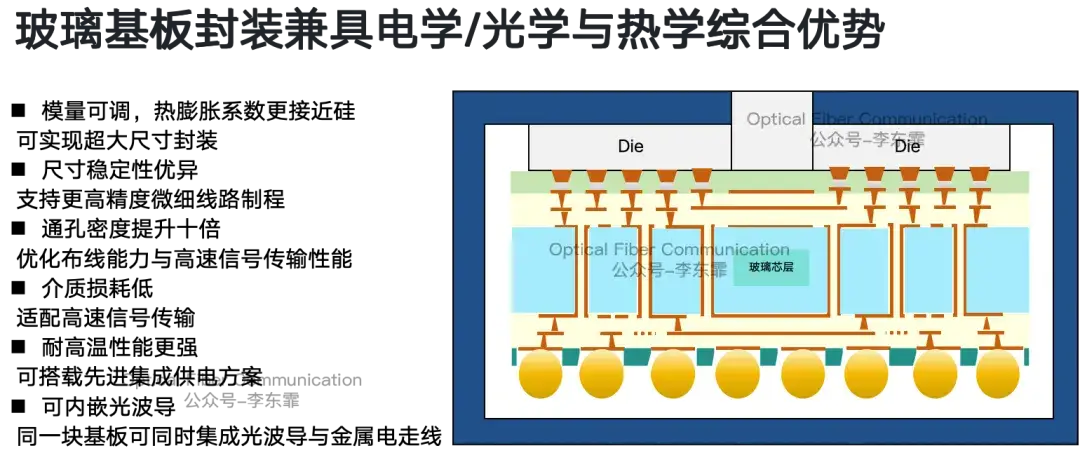
用光通道替代绝大多数铜线后,光波导的单位距离损耗远低于铜线,从根本上规避了高频趋肤效应带来的射频损耗。
OMIB 玻璃基板 Optical I/O 光互联的时延几乎不随走线距离增加而变化。

最后做一个简要对比。

欢迎订阅我们的专栏:
第二期 100 篇合集:前沿硅光+芯片+光器件与模块技术解析
若有不准确的地方烦请指正。